언어 모델링(Language modeling)
영어 문장 생성기처럼 기계가 사람의 언어와 관련된 작업을 수행하도록 하는 애플리케이션이다.
서스키버(sutskever), 마틴(martens), 힌튼(hinton)…
입력: 텍스트 문서
출력: 새로운 텍스트를 생성해서 출력
글자 단위 언어 모델리에서 입력은 글자의 신퀀스로 나뉘어 한 번에 글자 하나씩 네트워크에 주입된다.
이전의 입력된 글짜들과 함께 새로운 글자를 처리하여 다음 글자를 예측한다.

data set
구텐베르크(Gutenberg) 프로젝트
쥘 베른(Jules Verne) 1874 <신비의 섬(The Mysetrious Island)>
$curl -O http://www.gutenberg.org/files/1268/1268-0.txt
import numpy as np
with open('/Users/csian/Desktop/CP/data_set/Language_modeling/1268-0.txt', 'r', encoding='UTF8') as fp:
text=fp.read()
start_indx=text.find('THE MYSTERIOUS ISLAND')
end_indx=text.find('End of the Project Gutenberg')
text=text[start_indx:end_indx]
char_set=set(text)
print('전체 길이:', len(text))
print('고유한 문자:', len(char_set))
전체 길이: 1112350
고유한 문자: 80
문자를 정수 인덱싱 & 매핑
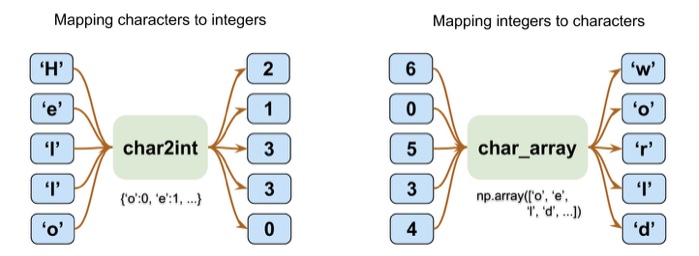
chars_sorted=sorted(char_set)
char2int={ch:i for i, ch in enumerate(chars_sorted)}
char_array=np.array(chars_sorted)
text_encoded=np.array([char2int[ch] for ch in text], dtype=np.int32)
print('인덱싱된 텍스트 크기:', text_encoded.shape)
print(text[:15], '==[인코딩]==> ', text_encoded[:15])
print(text_encoded[15:21], '==[디코딩]==> ', ''.join(char_array[text_encoded[15:21]]))
THE MYSTERIOUS ==[인코딩]==> [44 32 29 1 37 48 43 44 29 42 33 39 45 43 1]
[33 43 36 25 38 28] ==[디코딩]==> ISLAND
numpy text_encoder를 텐서플로 데이터셋으로 변환
import tensorflow as tf
ds_text_encoded=tf.data.Dataset.from_tensor_slices(text_encoded)
for ex in ds_text_encoded.take(5):
print('{} -> {}'.format(ex.numpy(), char_array[ex.numpy()]))
44 -> T
32 -> H
29 -> E
1 ->
37 -> M
입력된 시퀀스를 이용해서 다음에 올 문자를 80개의 고유문자 중 1개로 분류해야 하는 다중 분류 작업이다.
입력 텐서 x의 시퀀스 길이는 생성된 텍스트의 품질에 영향을 미친다.
긴 시퀀스가 더 의미 있는 문자을 만들 수 있다.
하지만 짧은 시퀀스일 경우 모델이 대부분 문맥을 무시하고 개별 단어를 정확히 감지하는 데 초점을 맞출 수 있다.
긴 시퀀스가 보통 더 의미있는 문장을 만들지만, 장기간 의존성을 감지하기 어렵다.
적절한 길이의 시퀀스 길이를 찾기 위해서 하이퍼파라미터 최적화 과정을 거쳐야 한다.
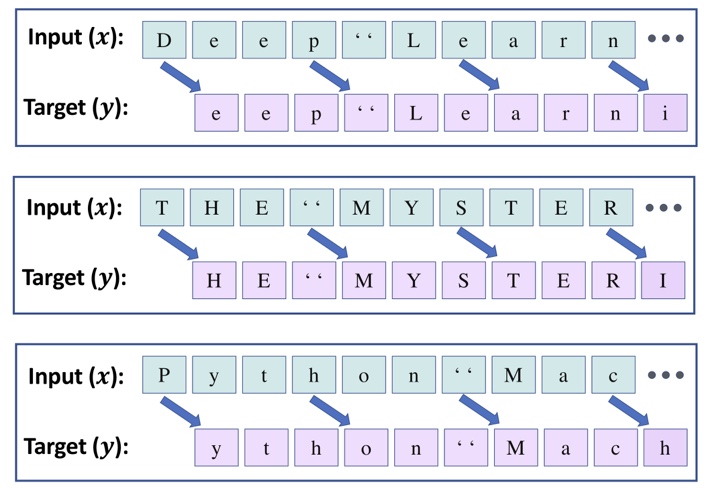
아래모델에서 텍스트 문자를 41글자씩 나누고, 앞 40문자를 입력 시퀀스 x가 되고, 뒤 40문자는 타깃 시퀀스 y가 된다.
x는 [0, 1, …, 39], y는 [1, 2, …, 40]
seq_length=40
chunk_size=seq_length+1
ds_chunks=ds_text_encoded.batch(chunk_size, drop_remainder=True)
def split_input_target(chunk):
input_seq=chunk[:-1]
target_seq=chunk[1:]
return input_seq, target_seq
ds_sequences=ds_chunks.map(split_input_target)
dataset test
for example in ds_sequences.take(2):
print('입력 (x): ', repr(''.join(char_array[example[0].numpy()])))
print('타깃 (y): ', repr(''.join(char_array[example[1].numpy()])))
입력 (x): 'THE MYSTERIOUS ISLAND ***\n\n\n\n\nProduced b'
타깃 (y): 'HE MYSTERIOUS ISLAND ***\n\n\n\n\nProduced by'
입력 (x): ' Anthony Matonak, and Trevor Carlson\n\n\n\n'
타깃 (y): 'Anthony Matonak, and Trevor Carlson\n\n\n\n\n'
Split MinitBatch
BATCH_SIZE=64
BUFFER_SIZE=10000
ds=ds_sequences.shuffle(BUFFER_SIZE).batch(BATCH_SIZE)